경희대에선 소프트웨어융합대학, 전자정보대학 학생들에게 GPU를 빌려준다.
물론, 학부생은 1인당 1개밖에 안빌려줌 ^^
원래는 GPU로 기계학습하라고 빌려주는 거긴 한데, 나는 대규모 데이터셋 전처리 하기 위해서 쓰게 되었음.
1. ssh [본인아이디]@[사용할 gpu 클러스터 이름].khu.ac.kr -p 30080 으로 로그인
ssh gykwak03@aurora.khu.ac.kr -p 30080
2. 작업할 경로로 이동
cd data/gykwak03/jupyter
3. 다음 명령어 입력
conda init
exec bash
4. conda activate [사용할 가상환경 이름]
conda activate yonsei
5. sbatch shell script 생성
vim [파일이름].sh
$ vim eICU.sh
6. 명령어 쓰고 :wq 명령어 사용하여 파일 저장
#!/bin/bash -l
#SBATCH -J jupyter # 작업 이름
#SBATCH --gres=gpu:1 # GPU 1개 할당
#SBATCH --cpus-per-gpu=8 # GPU당 8개의 CPU 할당
#SBATCH --mem=32G # 32GB 메모리 할당
#SBATCH -p batch_ugrad # 사용할 파티션 (적절히 변경)
#SBATCH -t 1-0 # 최대 실행 시간 (1일)
#SBATCH -o logs/jupyter-log-%J.txt # 출력 로그 파일
#SBATCH -e logs/jupyter-error-%J.txt # 에러 로그 파일
# Conda 초기화
source /data/gykwak03/anaconda3/etc/profile.d/conda.sh
# Conda 환경 활성화
echo "Activating Conda environment..."
conda activate yonsei # 'yonsei'는 실제 사용하는 Conda 환경 이름
# Conda 환경 활성화 확인 메시지
echo "Conda environment activated."
# 서버 IP 주소 출력
echo "Server IP: $(hostname -I)"
# Jupyter Notebook 실행
echo "Starting Jupyter Notebook..."
jupyter-notebook --no-browser --ip=0.0.0.0 --port=8888
7. mkdir 로 logs 파일 만들어줌
mkdir logs
8. sbatch shell script 실행
sbatch [파일이름].sh
sbatch eICU.sh(yonsei) gykwak03@aurora-master:/data/gykwak03/jupyter$ sbatch eICU.sh
sbatch: AURORA: Job submitted
Submitted batch job 31623
그럼 이런식으로 뜨는데 저 5자리 숫자 기억 기억 ㄱㄱ
9. 잘 실행되는지 로그파일 확인
cat /data/gykwak03/jupyter/logs/jupyter-error-31623.txt
9-1. nvidia driver 인식해야 하므로 다음 명령어 출력
srun --jobid=31623 --pty bash
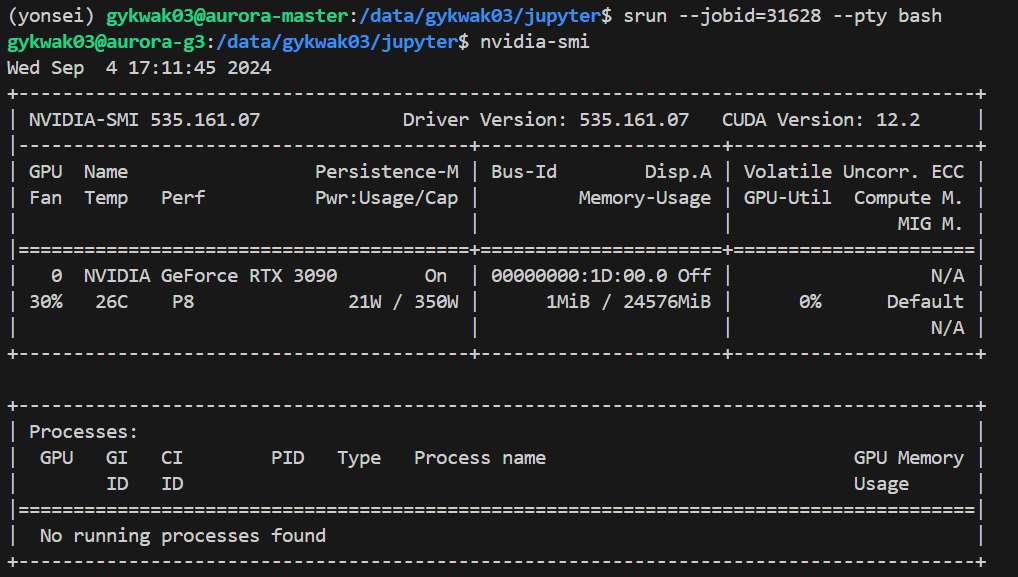
저거 해야 다음과 같이 인식됨
10. 주피터 노트북 열기
jupyter notebook --ip=$(hostname -i)
그러면 이런식으로 뜨는데 저기 가린 부분에 url 링크가 뜰거임 그거 타고 드가면 됨