1. Introduction
전이 학습이란, 이미 학습된 모델을 다른 작업에 활용하는 것을 말한다. 그 예시중엔 fine tuning이 있다. 그런데, fine tuning을 하려면, 10억(1B)개의 파라미터를 가진 LLM을 full fine-tuning(32bit 부동소수점)하려면, 24GB의 메모리가 필요하다. 따라서, 메모리 최적화 없이 LLM을 파인튜닝하면 OOM(Out of Memory)에러가 맨날 뜨는 것을 볼 수 있다. 이 논문에서는 LLM 파인튜닝을 위한 대표적인 최적화 기법들에 대해 자세히 소개하고, 메모리 사용량과 실행 시간 사이의 절충 관계를(trade-off) 분석하며, 실험 결과를 통해 최적의 조합을 선택하기 위한 가이드라인과 기준점을 제시한다.
2. Related Work
1. 병렬화 전략
- Tensor parallelism
모델의 연산(행렬 계산 등)을 여러 GPU가 조금씩 나누어서 동시에 처리하는 기법이다. 예를 들어, 큰 행렬 곱셈을 계산해야 할 때, 각 GPU가 각 행렬의 일부분을 계산한다.
- Pipeline parallelism
모델의 신경 층(layer)을 나누어서 GPU 여러 대에 분산시키는 방법이다.
- ZeRO(Zero Redundancy Optimizer)
기존 딥러닝 모델의 분산 학습에서는 데이터는 분산되지만 모델 학습을 위한 값(optimizer state, gradient, parameter)는 각 GPU마다 복제해서 가지고 있어야 했다. (Microsoft에서 GPT2모델이 3GB 밖에 안되는데도 불구하고, 32GB GPU에서 OOM이 뜨는 것에서, 나머지 메모리가 모델 학습을 위한 값들이 차지하는 것을 알 수 있었음)
ZeRO는 데이터 및 모델 병렬화를 통합하여, 모델 상태를 분할 저장하고 학습 중 필요할 때 이를 재구성한다.
ZeRO는 deepspeed에서 사용 가능
ZeRO에는 3가지 최적화 단계가 있음
1. Optimizer State Partitioning(Pos) : 메모리 4배 감소
2. Add Gradient Partitioning(Pos + g) : 메모리 8배 감소
3. Add Parameter Partitioning(Pos+g+p) : 메모리 GPU 개수만큼 감소
단계가 높아질 수록 더 많은 메모리 절약이 가능하지만, 학습 시간은 오래 걸림
또한, ZeRO-Offload(옵티마이저 상태를 CPU로 오프로드), ZeRO-Infinity(모델 파라미터를 메모리 외부로 이동)기법도 존재.
- FSDP(Fully Sharded Data Parallel)
Zero Stage 3과 거의 유사한 방식으로 parameter sharding, pytorch에서 기본 제공
2. PEFT (Parameter-Efficient Fine Tuning)
PEFT는 전체 모델 파라미터 중 일부분만 수정하고, 나머지는 학습 중 고정시킨다. PEFT 기법으로는 Prefix Tuning과 Prompt Tuning 등이 있다. 하지만 이보다 더 자주 쓰이는 것은 **LoRA(Low Rank Adaptation)**이다.
사전학습된 모델의 가중치는 그대로 고정하고, 각 transformer 층에 rank decomposition matrices를 삽입하여 일부만 업데이트 하는 기법이다. 이러한 방식으로 학습할 파라미터를 수십~수백배 줄일 수 있다.
예를 들어, 70B 파라미터 모델에 대해 LoRA rank를 64로 설정하면, 학습 파라미터 수는 약 1억 3100만개로 줄어든다.
PEFT 기법은 ZeRO와 같은 병렬화 기법과도 쉽게 통합할 수 있어, 파인튜닝 중 메모리 및 시간 감소 측면에서 이점을 파악할 수 있다.
- Prompt Tuning: 모델 입력에 학습 가능한 가짜 토큰들(임베딩)을 앞에 붙여서, 그 토큰 벡터들만 훈련시키는 기법
(가짜 임베딩들을 보고, 이게 요약하려는 task 인지, 분류하라는 task 인지 사용자가 언급하지 않아도 실행하도록 하게 함) - Prefix Tuning: Prompt Tuning과 비슷하지만, 모델 내부에 가짜 컨텍스트를 넣는 방식이다.
3. Gradient Checkpointing
Gradient Checkpointing이란, 순전파 중에 생성되는 모든 activation(활성값)을 저장하지 않고, 필요한 순간(역전파 시간)에 다시 계산하는 방식으로 GPU 메모리를 아낄 수 있다. 메모리 사용을 가장 효율적으로 줄이는 전략은 딥러닝 모델의 계층 수(n)의 제곱근 단계마다 체크포인트를 저장하는 방식이다. 따라서 20~30%정도 학습 시간은 늘어나지만, n의 제곱근 수준으로 메모리 사용량이 줄어든다.
4. FlashAttention
attention 연산은 컨텍스트 길이가 길 경우 메모리 병목의 원인이 된다. FlashAttention은 Attention 연산의 복잡도를 선형 수준으로 낮추어, 소비되는 메모리를 최적화하는 데 중점을 둔 기법이다. Tiling(연산을 작은 조각으로 나눔), Recomputing(일부 값을 필요할 때만 다시 계산)이 메인 기법이다. 특히, GPU 안에서 가장 빠르지만 용량이 적은 SRAM을 효과적으로 활용하여 SRAM과 HBM 간의 읽기/쓰기 횟수를 최소화하여 속도를 높인다. Gradient Checkpointing과 FlashAttention은 모두 PEFT, ZeRO와 결합하여 사용할 수 있다.
여러 전략들이 있지만, 이들 모두를 다 쓰는 것이 항상 좋은 것은 아니다.
서로 호환 가능한 방법들이어도, 메모리, 실행 시간, 정확도 간의 트레이드오프가 존재하기 때문에 골라 써야 한다.
기존에도 여러 가이드라인이 있었지만, 본 연구처럼 최적화 조합의 실제 효과를 분석한 연구는 드물다.
3. Theoretical Analysis of GPU Memory Requirements
메모리 사용의 3가지 주요 요소 :
- Model States ( parameter, gradient, optimizer state)
- Activations 순전파/역전파 중 계산되는 중간 결과
- Temporary Buffers & Fragmentation: 시스템 내부에서 임시로 사용하는 메모리 공간
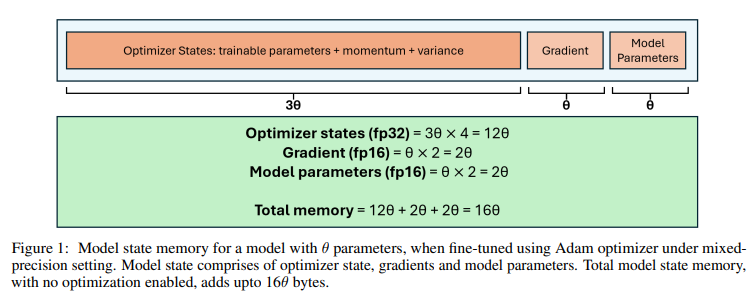
1. Model States Memory
parameter 개수를 θ라고 하자.
parameter
float16(2byte)로 저장된다. 따라서 2θ
gradient
역시 float16(2byte)로 저장된다. 따라서 2θ
Optimizer State
Adam Optimizer는 각 parameter마다 3개의 값을 유지해야 한다: parameter 자체, 모멘텀, 분산이다. 각 값은 float32(4byte)이다. 옵티마이저 상태는 12θ가 된다.
=> Model States Memory는 총 16θ 바이트가 된다.
2. Activation Memory
Activation Memory는 다음과 같은 수식으로 근사한다.
s = sequence length , b = microbatch size, h = hidden dimention size, a = number of attention head

위 수식에 전체 레이어 수를 곱하면, Activation Memory가 계산된다.
결론적으로,

표 1은 LlaMa 70B 파라미터 모델을 ZeRO-DP 단계에서 finetuning할 때, 이론적으로 예상되는 GPU 메모리와 실제 사용되는 GPU 메모리를 비교한 결과를 보여준다. ZeRO-1, ZeRO-2, ZeRO-3은 각각 ZeRO-DP의 1단계, 2단계, 3단계를 의미한다. 이 실험결과를 통해서, 옵티마이저 상태를 CPU로 오프로드하면, 그렇지 않을 때보다 GPU 메모리 사용량을 최대 4배 줄일 수 있음을 시사한다.
참고로, ZeRO-DP 같은 최적화를 전혀 사용하지 않고, 기존 방식의 데이터 병렬화로만 70억 파라미터 모델을 파인튜닝하려면 112GB 이상 (16 × 7)의 GPU 메모리가 필요하다. ZeRO 없이 A100 한 개로는 파인튜닝이 불가능하다는 이야기다.
4. Experiments
4.1 Setup
이 실험에서 등장하는 Config는 다음과 같다.
Models : LlaMa2(7B, 13B, 70B), Falcon 180B
Dataset : Samsum 데이터셋
Compute : Standard_ND40rs_v2 (8개의 V100 GPU), Standard_ND96amsr_A100_v4 (8개의 A100 GPU)
Optimizer : AdamW(β₁ = 0.9, β₂ = 0.99), learning rate = 4e-4, linear scheduler, mixed precision
Sequence length : 256( 시퀀스 길이 변화 실험에서는 padding을 통해 길이를 확장)
batch size : 8, gradient accumulation을 사용해 실효 배치 사이즈를 증가시켜 GPU 메모리를 효율적으로 사용
epoch : 1
LoRA 설정 (LoRA 실험 시) : rank 64, alpha 32
CPU Offload : ZeRO-Offload를 사용하여 옵티마이저 상태와 연산을 CPU로 오프로드
GPU 메모리 사용량은 파인튜닝 중 모든 GPU에서 측정된 최대 피크 메모리 사용량을 기준으로 계산
4.2 Best Default Optimizations to Balance Memory and Runtime
이 부분에선 어떤 설정이 메모리 사용량과 실행 시간 사이에서 가장 좋은 균형을 만드는지를 실험하였다. LlaMa 2 7B 모델로, A100 GPU 1노드(8개)를 사용하여, 아래 5가지 조합으로 실험하였다.
- 아무 최적화도 없음 (None)
- Gradient Checkpointing (GC)**만 사용
- GC + LoRA + FlashAttention2 (FA2)
- GC + LoRA + FA2 (단, CPU Offload 사용 안 함)
- 최적화 없이 CPU Offload만 제외
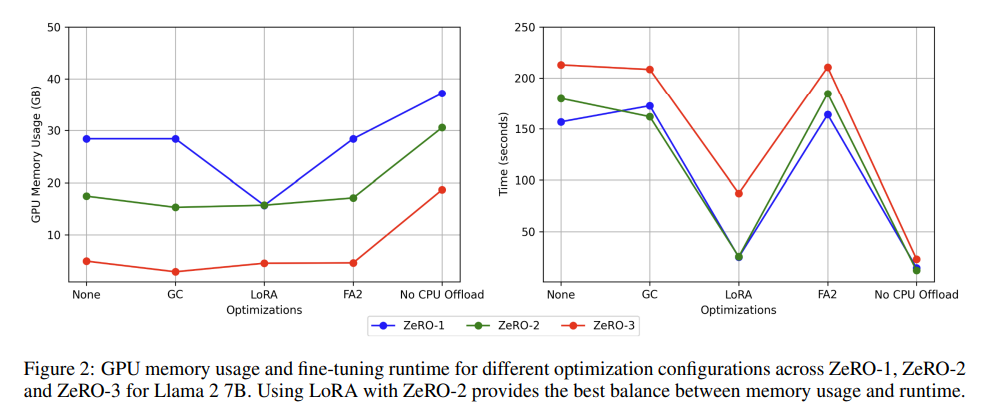
전체적으로 3번째 조합이 가장 우수했다. 메모리와 실행 시간 둘다 잘 절약해주었다. 3번재 구성에서 ZeRO-1과 ZeRO-2의 메모리 사용량과 실행 시간 차이는 거의 존재하지 않았다. LoRA(rank=64)를 적용했을 때, 70억 파라미터 모델의 학습 가능한 파라미터 수는 약 3,360만 개로 줄어든다.
첫번째와 네번재 조합에선 ZeRO 단계에 따라 메모리는 감소하고, 실행 시간은 1 2 3 순으로 증가하는 일반적인 경향을 보였다.
두번재와 다섯번재 조합에선 ZeRO-1에서 실행시간이 ZeRO-2보다 약간 더 길었지만, ZeRO 단계가 올라갈수록 메모리 사용량은 줄어드는 일반적인 추세를 보였다.
다섯번째 구성이 실행 시간은 가장 빠르지만, GPU 메모리는 2-4배 더 많이 소요된다.
결론적으로, ZeRO-2와 LoRA의 조합이 메모리 사용량과 실행 시간 사이의 균형을 잘 유지할 수 있게 해주기 때문에, 이를 default로 채택한다. 그러나 복잡한 QA Task나 챗봇 개발에 있어선, 사용자가 전체 모델을 fine-tuning하는 것을 선호할 수도 있기 때문에, 이는 사용자의 선택에 달려 있다. ZeRO-2는 파인튜닝 과정에서 기본적으로 활성화할 것을 권장한다.
4.3 Fine-tuning Large Models
LlaMa 2 70B, 혹은 Falcon 180B와 같은 대형 모델을 파인튜닝할 경우, 적절한 최적화 기법을 사용하지 않으면 OOM 오류가 뜬다. 이때, ZeRO-3 을 활성화하는 것이 좋은 대안이 될 수 있지만, 그에 따라 실행 시간이 늘어날 수 있다.

예를 들어, 100B 파라미터 모델을 5개의 노드에서 파인튜닝하면, 필요한 모델 메모리는 40GB가 된다. (100 * 16/ 5*8)
이는A100 80GB에 충분히 들어가는 양이지만, 이때 필요한 GPU는 40개이다.
실제로는, 수백억~수천억 파라미터 모델을 파인튜닝할 때 LoRA와 ZeRO-3의 CPU 오프로드 기능을 함께 사용하는 경우가 많다.
이 섹션에선 LlaMa 2 70B 모델을 ZeRO-3, LoRA 조합으로, GPU 8개인 단일 노드에서 실험한다.

표 2에 따르면, 70B 모델의 실제 GPU 메모리 사용량은 약 15.54GB였다. 13B, 7B 모델은 GPU 메모리가 매우 남아도는 것을 볼 수 있었다. 작은 모델에 있어서 ZeRO-3과 LoRA는 과도한 설정일 수 있다. 이를 통해, finetuning에 있어서 ZeRO-3은 필수적임을 보여준다.
4.4 Long Context Fine Tuning

Context Length (한번에 처리하는 텍스트 길이)가 길어지면, 그에 따른 연산량도 길어진다. FlashAttention2 를 사용하지 않으면, Attention연산량이 길이에 따라 제곱으로 증가한다.
긴 문장이 학습에 어떤 영향을 주는지 확인하고자, LlaMa 2 70B 모델을 대상으로 컨텍스트 길이를 1024 2048 4096으로 바꾸면서, GPU 메모리 사용량과 학습 시간이 어떻게 변하는지 측정하였다.
장비: 8xA100, 8xV100 (V100은 FA2 지원 X)
설정: ZeRO-3 + LoRA + GC(Gradient Checkpointing)
컨텍스트 길이가 길어질수록, FA2를 쓰는 쪽이 확실히 효율이 좋아지는 것을 볼 수 있었다. A100 같은 고성능 GPU는 큰 용량의 HBM 덕분에, FlashAttention2 없이도 긴 context length를 어느 정도 잘 처리할 수 있다. 그러나 FA2를 함께 활성화할 경우, 메모리 절약과 학습 시간 단축 면에서 추가적인 이점이 크다.
4.5 Fine-tuning under GPU Resource Constraints
이 섹션에선 파라미터 수가 7B에서 180B 사이인 LLM을 제한된 리소스 내에서 파인튜닝하는 것을 논의한다. 여기서 제한된 자원이란, 제한된 HBM 만을 사용할 수 있으며, 사용할 수 있는 GPU 수도 적을 때를 의미한다. 이 실험에선 V100 GPU 8개, HBM 32GB를 사용하였다. Falcon 180B 모델만 모델 크기로 인해 파인튜닝에 두개의 노드 (총 16개의 V100 GPU만을 사용하였다)

그림 4는 GPU 메모리 요구 사항을 만족시키면서도 실행 시간을 최적화할 수 있는 권장 설정들을 보여준다.성공적인 파인튜닝을 가능하게 하는 다른 설정 조합들도 존재하지만, 논문은 최소한의 파인튜닝 시간을 제공하는 설정을 선택했다.
이 실험을 통해 얻은 인사이트는,
1. 모델 병렬 처리와 데이터 병렬 처리의 결합은, 7B처럼 작은 모델을 양자화시키지 않는다면 적은 수의 GPU로 학습시키기 위해서도 필수적이다.
2. Context length나 모델 크기가 커질 수록, 보다 높은 단계의 ZeRO로 변환하는 것이 중요해진다.
3. Gradient Checkpointing은 대규모 모델일 수록 메모리를 절약하는 효과적인 최적화 기법이다.
( 그림 4에서 보이듯, Llama 2의 13B 및 70B 모델에서 GC를 사용했기 때문에 context length를 512~4096까지 지원할 수 있었으며, GC 없이는 불가능했을 것이다)
4. FlashAttention-2는 V100 GPU에서는 지원되지 않았지만, 지원되는 플랫폼에서는 항상 사용하는 것이 좋다는 결과를 얻었다.
https://arxiv.org/abs/2406.02290
A Study of Optimizations for Fine-tuning Large Language Models
Fine-tuning large language models is a popular choice among users trying to adapt them for specific applications. However, fine-tuning these models is a demanding task because the user has to examine several factors, such as resource budget, runtime, model
arxiv.org