[논문 리뷰] LLM4FS: Leveraging Large Language Models for Feature Selection and How to Improve It
Introduction
특징 선택(feature selection)은 최적화 및 인공지능 분야에서 핵심적인 단계로, 고차원 데이터에서 성능을 높이고 계산 효율을 개선하기 위해 가장 유용한 변수들만 골라내는 작업. 크게 3가지 방법으로 나눌 수 있다
1. Filter Method : 변수와 목표값 간의 상관관계를 계산하여, 중요도가 높은 순서대로 변수를 선택하는 방법
ex) Pearson correlation, Chi-square, Mutual Information
2. Wrapper Method : 다양한 변수 조합을 만들어 실제 모델에 적용해보고, 성능이 가장 좋은 조합을 찾는 방법
ex) Forward Selection, Backward Elimination, Recursive Feature Elimination (RFE)
3. Embedded Method : 모델이 학습되는 과정에서 중요하지 않은 변수는 자동으로 제외되도록 설계하는 방식
ex) LASSO, Decision Tree, XGBoost
LLM은 뛰어난 추론 능력을 가지고 있는 반면, 전통 ML 모델들은 높은 신뢰성과 검증된 정확도를 가지고 있음
-> LLM이 전통 ML의 장점을 직접 활용할 순 없을까?
Contributions
- 최신 LLM들을 다양한 데이터셋에 적용하여 특징 선택 성능을 비교
- LLM4FS 제안 : LLM의 의미 추론 능력과 전통 기법의 통계적 기반을 결합한 하이브리드 전략
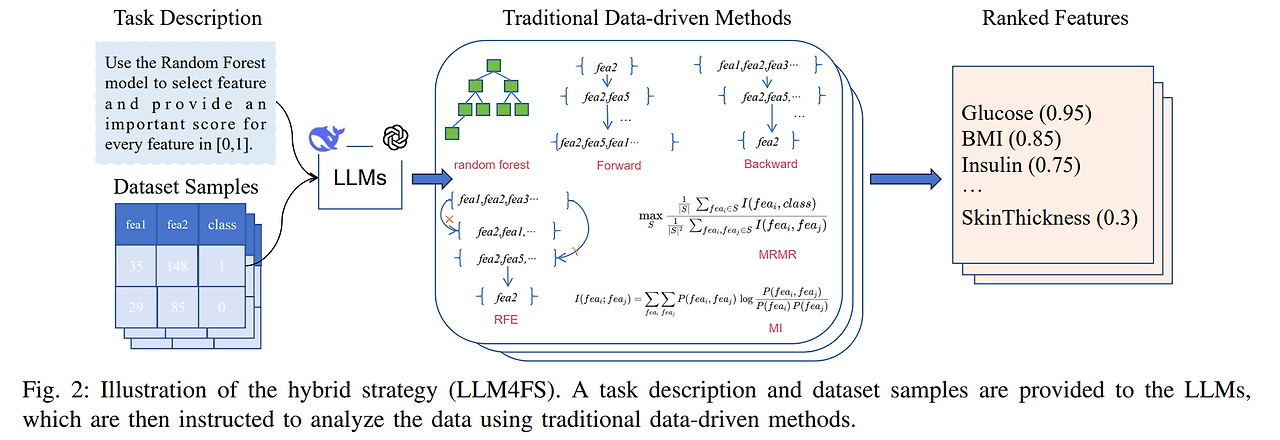
Methods
1. LLMs-based Method : LLM이 각 변수(feature)의 중요성을 자신의 지식과 경험을 바탕으로 의미적으로 평가하도록 유도
2. LLM4FS
전체 데이터의 약 20% 이하인, 샘플 약 200여개를 LLM에게 전달하고, 그 데이터를 분석할 때 LLM이 전통적인 기법( random forest, forward sequential selection, backward sequential selection, recursive feature elimination (RFE), minimum redundancy maximum relevance (MRMR), and mutual information (MI))을 적용하도록 요청

Experiment
1.Datasets
- Bank
- Credit-G
- Pima Indians Diabetes
- Give Me Some Credit
2. LLM
LLM의 특징 선택 성능을 살펴보기 위해, 최신 모델 3가지 사용 ( temperature T=0.1 )
- DeepSeek-R1 (DS-R1) – 2025년 1월 20일 버전
- GPT-o3-mini (GPT-o3m) – 2025년 1월 31일 버전
- GPT-4.5 – 2025년 2월 27일 버전
GPT-4.5는 사용 제한이 있어, 우리가 제안한 LLM4FS 하이브리드 전략에서는
GPT-o3-mini와 DeepSeek-R1 두 모델만 사용
3. Baseline
- LASSO [17]
- Forward Sequential Selection (순방향 선택)
- Backward Sequential Selection (역방향 선택)
- Recursive Feature Elimination (RFE) [18]
- Minimum Redundancy Maximum Relevance (MRMR) [19]
- Mutual Information (MI) [20]
- Random Feature Selection (무작위 선택)
또한, 하이브리드 전략 LLM4FS에서는 비교 기준 중 하나로
**랜덤 포레스트(Random Forest)**도 함께 사용
4. 구현 및 평가 방법
각 특징 선택 방법은 선택된 특징의 비율이 10%에서 100%까지 증가함에 따라, 후속 분류 모델의 테스트 성능이 어떻게 변하는지를 기준으로 평가
분류 수행 모델은 logistic regression 사용
lasso를 제외한 모델들은 l2 normalized logistic regression model , lasso 모델은 l1 normalized logistic regression model 사용
Result

Result 1. 일부 상황에서는 LLM 기반 방법들이 전통적인 방식보다 성능이 약간 낮게 나오기도 하지만, 전체적으로는 매우 유사한 수준의 성능
특히 Credit-G와 Give Me Some Credit 데이터셋에서는 DeepSeek-R1이 강력한 가능성을 보여주며, LLM이 특징 선택 작업에서 유망한 도구가 될 수 있음을 시사

Result 2. LLM4FS는 성능을 한층 더 향상시킨다.
파란색 바보다 앞서나가있는 초록색 바 존재
- LLM이 고작 200개 샘플만 보고도, 전통적인 특징 선택 방법을 잘 활용
- 실제로 LLM이 만들어낸 코드를 실제로 실행해봤더니, LLM이 텍스트로 출력했던 점수와 똑같은 점수들 도출
-> LLM이 정말로 랜덤 포레스트나 순차 선택 등 전통 기법을 내부적으로 실행하고 있다는 증거
- LLM이 사용하는 특징 선택용 모델과 후속 평가용 분류 모델이 다르기 때문에, 서로의 강점을 보완하면서 전체적인 성능이 오히려 향상되었을 가능성 존재

Result 3. DeepSeek-R1은 성능도 뛰어나고 비용 효율도 우수
Fig. 3에서 보이듯 DeepSeek-R1은 GPT-4.5와 유사한 성능을 내고 있으며,
하이브리드 전략(LLM4FS)에서도 우수함을 입증했습니다(Fig. 4 참고).
또한, GPT-o3-mini는 모델 크기가 작기 때문에
간혹 부정확하거나 이상한 값을 출력하는 경우가 있었지만,
DeepSeek-R1에서는 그런 문제가 거의 없었습니다.
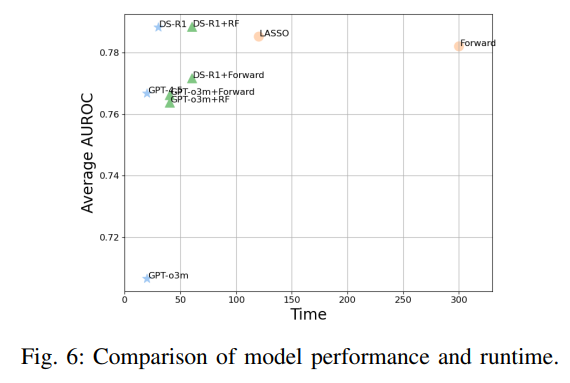
Result 4. LLM 방식과 하이브리드 전략은 빠르게 특징을 선택할 수 있음

다만, 속도가 빠른 만큼 성능은 약간 낮아질 수도 있습니다.
하지만 DeepSeek-R1과 DeepSeek-R1 + RF 조합은
속도와 성능 간 균형을 잘 유지하며 오히려 전반적인 성능도 향상

Result 5. DeepSeek-R1은 10~30% 변수만 사용할 때도 안정적으로 성능을 냄
Fig. 7을 보면, 어떤 방법도 10~30% 변수만 사용했을 때 항상 최고의 성능을 내는 건 아니지만,
DeepSeek-R1과 DeepSeek-R1 + RF 조합은
전체적으로 안정적이고 꾸준한 성능을 보여주었습니다.
단, Pima Indians Diabetes 데이터셋의 30% 구간에서는 다소 성능이 떨어졌지만,
다른 데이터셋에서는 일관되게 좋은 결과를 보였습니다.
또한 Credit-G 데이터셋에서는 초반에 DeepSeek-R1+RF의 성능이 떨어졌지만,
30% 변수 기준에서는 가장 높은 성능을 기록하며 반등